[Warning: long post, of uncertain value, with annoyingly uncertain conclusions.]
This post will focus on how hardware (cpu power) will affect AGI timelines. I will undoubtedly overlook some important considerations; this is just a model of some important effects that I understand how to analyze.
I’ll make some effort to approach this as if I were thinking about AGI timelines for the first time, and focusing on strategies that I use in other domains.
I’m something like 60% confident that the most important factor in the speed of AI takeoff will be the availability of computing power.
I’ll focus here on the time to human-level AGI, but I suspect this reasoning implies getting from there to superintelligence at speeds that Bostrom would classify as slow or moderate.
Why focus on hardware? Part 1: Evidence from software
Progress in algorithms seems comparable to hardware progress in a number of domains. Robin Hanson argues that that is most plausibly explained by hardware progress causing algorithmic progress [1].
I expect that when algorithmic progress is similar to hardware progress, it’s due to getting enough cpu power to test many algorithms. But this model suggests that algorithmic progress should stop in many domains due to people finding near-optimal algorithms.
I suspect the alleged algorithmic progress is mostly due to selection effects – people rarely study algorithmic progress in domains where progress has slowed.
Here are some domains where I suspect a careful analysis would show that algorithmic progress has become unimportant compared to hardware progress:
- file compression (see the Hutter prize: longer run-time to produce a few percent better results; and the Calgary Corpus, where progress is clearly slowing.
- search, specialized for Google-type query
- queries on databases such as Oracle
- compilers (both speed of compilation for a given language, and how fast the resulting code runs)
- sorting
- Cooper’s Law of spectral efficiency (a trend in wireless communication that looks like Moore’s law, but is too old to be explained by semiconductor progress). I suspect that if much of this were due to improved wireless algorithms, Katja would have found and analyzed evidence of that algorithmic improvement.
Eliezer has claimed that AlphaGoZero is evidence for the importance of algorithmic progress. But AlphaGoZero looks like something that could have been discovered by trial and error given ML knowledge from 2015 and hardware from 2020.
Part 2: Evidence from ML researchers
I’ve seen frequent claims from ML researchers that hardware is one of the most important factors affecting their progress.
C.f. Hinton’s summary of the main problems that needed to be solved make neural nets powerful:
- Our labeled datasets were thousands of times too small.
- Our computers were millions of times too slow.
- We initialized the weights in a stupid way.
- We used the wrong type of non-linearity.
I’m guessing that labeled datasets will become less important because the field is maturing in ways that allow it to rely more on unsupervised learning. E.g. Hinton says
We clearly don’t need all the labeled data.
The insight about initializing weights looks like evidence in favor of the idea that AI progress results from better theories/algorithms.
But the non-linearity breakthrough points in the opposite direction: theories about the need for differentiability delayed the discovery of ReLU’s benefits, and even now that we know it’s an improvement, it’s a bit hard to explain why. This seems like the kind of blind empiricism that should be expected if algorithmic progress were primarily driven by hardware progress enabling researchers to test more hypotheses.
So for these four factors, I’d say (2) is clear evidence for progress depending on hardware, (4) is weak evidence for that, (3) is mild evidence against it, and I don’t see how to infer much from (1).
I expect the leading deep learning researchers to overstate the value that they have been adding to AI progress, which suggests they understate the importance of hardware by some unknown amount. At a recent conference on AI and longevity, where speakers were mainly showing off their biomedical expertise, speakers mentioned falling hardware costs and more data as reasons why this is a good time to apply AI to medicine. They were using some moderately new techniques such as GANs, but didn’t suggest those techniques were why AI/deep learning is interesting now.
It hasn’t just been deep learning researchers who say hardware matters – the leading genetic programming advocate has said something similar.
Part 3: Evidence from theory
José Hernández-Orallo’s The Measure of All Minds describes a subset of intelligence which requires exponentially increasing resources to produce linear gains in an objective IQ-like measure of intelligence. It’s unclear whether that’s of much practical significance (maybe it suggests we should think of IQ as measuring the log of intelligence?), but it does seem to provide a lower bound for the hardware needed for various levels of intelligence.
Part 4: Evidence from evolution
The best cross-species IQ-like tests show IQ varies with log of brain size (see Deaner 2007, MacLean 2014).
Most mammalian brains scale poorly. For non-primates, the mass of the cerebral cortex increases exponentially polynomially (exponent of 1.6) with the number of cortical neurons. The best guess is that the number of neurons is the best predictor of intelligence. Primates have an adaptation which causes that scaling to be linear (see Suzana Herculano-Houzel’s The Human Advantage: A New Understanding of How Our Brain Became Remarkable, figures 4.8 and 4.9). Without that adaptation, it looks like matching the human cortex requires a whale-sized body.
Large primates show clear evidence of brain size being energy limited, given their foraging patterns. Gorillas and orangutans evolved exception to the typical primate scaling because they couldn’t afford to feed a bigger brain (i.e. they evolved smaller brains than the primate pattern predicts; they’re foraging and feeding about 8-9 hours per day, which seems to be the limit of what primates can sustain) (Herculano-Houzel, figures 5.5 and 10.2). That suggests there was significant selective pressure for the largest brain that primates could feed.
The main reason that humans outsmart other apes in some important contexts is due to our improved ability to build on each others knowledge (see The Secret of Our Success: How Culture Is Driving Human Evolution, Domesticating Our Species, and Making Us Smarter, by Joseph Henrich (“We stand on the shoulders of a very large pyramid of hobbits”)). I.e. we derive more benefit from each others processing power than do other species. A secondary reason is our larger brain size, which required that accumulation of cultural knowledge in order to get enough food to fuel big brains.
Henrich has convinced me that for algorithms which are more general-purpose than, say, language, humans are running the same algorithms as other large primates. That’s what I’d expect if evolution had found sufficiently good “general intelligence algorithms” that most evolutionary intelligence increases were due to something else.
There’s a sense in which algorithmic progress mattered for humans superiority over apes: humans devote more effort to developing general purpose tools such as language. But that’s a weaker sense than an improvement in the basic algorithms for general intelligence that Eliezer seems to imply (although I can’t find an unambiguous claim to that effect).
ML researchers seem to be converging on algorithms that have comparable efficiency to the features of primate brains that have been subjected to selection over long time periods. That’s further evidence that they’re somewhat close to optimal at tasks they do, while leaving open the possibility of additional general-purpose tools that improve performance in novel domains.
Guesses about hardware trends, part 1: Physics
How long will Moore’s Law-like trends continue?
Moore’s Law hit a speed bump around 2004 when clock speeds stopped increasing [2]. That put constraints on what kind of software could benefit from other ways to speed up the hardware (i.e. parallelism).
It will hit a bigger speed bump around 2021 or 2022, when it runs into the Landauer limit that will stop the standard version of Moore’s Law (dealing with chip density).
Progress after that is less certain, because it requires strategies that look very different from shrinking the feature size. Those strategies seem likely to put greater constraints on what software can benefit from the improved hardware.
My impression of expert opinion is that it implies that FLOPS/dollar will continue increasing at Moore’s Law-like rates through at least 2030 for neural nets, but energy efficiency trends will slow in the 2020s.
On the other hand, Wikipedia’s page on energy efficiency trends (Koomey’s lawJake Cannell in which he claimed neurons operate about an order of magnitude above the Landauer limit (i.e. close to where errors would start to complicate the computations). Eliezer has suggested it’s more like six orders of magnitude. Anders Sandberg seems to have studied the issue more carefully, and is relatively uncertain, but sees a good deal of room for improving on nature.
Guesses about hardware trends, part 2: Economics
Physics considerations may tell us about some important limits, but I don’t see signs that they tell us much about manufacturing costs. Experience curve effects have a better track record for that purpose.
So I’ll try to estimate the trends in AI-relevant hardware, by predicting the increase in cumulative shipments of AI-relevant hardware. Alas, that’s hard.
The Moore’s law trend for processors in general tells us something, but the divergence between GPU trends and CPU trends suggests I should focus on the trends in increasingly specialized processors.
Ideally, I’d estimate the trend in cumulative shipments of TPUs, and extrapolate from that. But I haven’t found enough data to pretend I’ve found a pattern.
Instead, I’ll look at trends in hardware that’s partly specialized for AI.
Looking back into the 1990s, it’s not clear how to count early versions of AI-related hardware. The Connection Machine and Cray machines were somewhat AI-oriented, but primarily specialized for other purposes. I’ll take the Connection Machine’s peak sales ($65 million in 1990) as a crude estimate of early AI-related hardware quantities. Some data points for Cray: $8.8 million in 1976, and a bit over $200 million in 2003. These suggest a growth rate of around 12%/year (but that’s dollars of sales, when what I want is growth in cumulative computing power, which is presumably higher). Maybe I should also include chess machines, which were sold in moderate quantities, but mainly at prices which supported toy-like quality, not cutting edge versions.
There was something of a phase change mid 2000s (coincidental with a phase change in AI research?), when Nvidia GPUs started to become more important than CPUs for AI. But should I extrapolate from total GPU shipments, or try to estimate a subset that goes more specifically toward AI? Nvidia reports recent datacenter and auto sales that are relatively AI-specific, but the datacenter sales seem rather erratic, and its auto sales (for robocar-like uses) almost certainly underestimate recent AI-related growth. But they provide enough data to say that growth is probably somewhere between 15% and 100% annual growth.
It seems likely that the commercial value of AI-related hardware will increase at exponential rates for at least a few decades, and that this will generate the increase in cumulative shipments which will drive an experience learning curve in the relevant manufacturing techniques. But there’s plenty of room for uncertainty about the exponent. Maybe much of the recent growth in AI-related GPU sales is driven by companies who mistakenly imagine they’re on the cutting edge (and will eventually notice that a much simpler statistical approach will work as well as the fancy techniques they’re trying). Or maybe TPU use represents a better estimate of AI hardware growth, and maybe TPU sales are growing faster than GPU sales.
I was tempted to infer from the recent Nvidia trends that I should use 15% annual growth in shipments as a lower bound for GPU/TPU growth rates. But then I noticed that Moore’s law was driven by roughly 15% growth in CPU shipments, at least in the 1995-2010 timeframe. I don’t see much reason for confidence that AI-related hardware quantities will increase at a faster rate than that, so I’m scaling back my estimates of GPU/TPU growth rates to make 15% roughly my median forecast (and concluding that a fair amount of the recent Nvidia growth is due to fads).
{kind=link}
On the other hand I see important demand for more AI-related hardware from robocars, possibly causing a big boost in GPU sales in the early 2020s. I also see steadier growth in demand for applying AI to customer service/support.
The growth in AI-related hardware over the next decade or so seems likely to resemble the hardware growth that drove Moore’s law in recent decades, so I think the best guess is that the cost of AI-related hardware will drop at rates that resemble those associated with Moore’s law.
Recent trends in the cost of computing suggest an order of magnitude drop in cost every 4 to 12 years, with the slower end of that range looking more realistic.
So I’m forecasting that the cost of AI-related computing will continue declining at around an order of magnitude per decade past 2030, and I’m reluctant to forecast much beyond that.
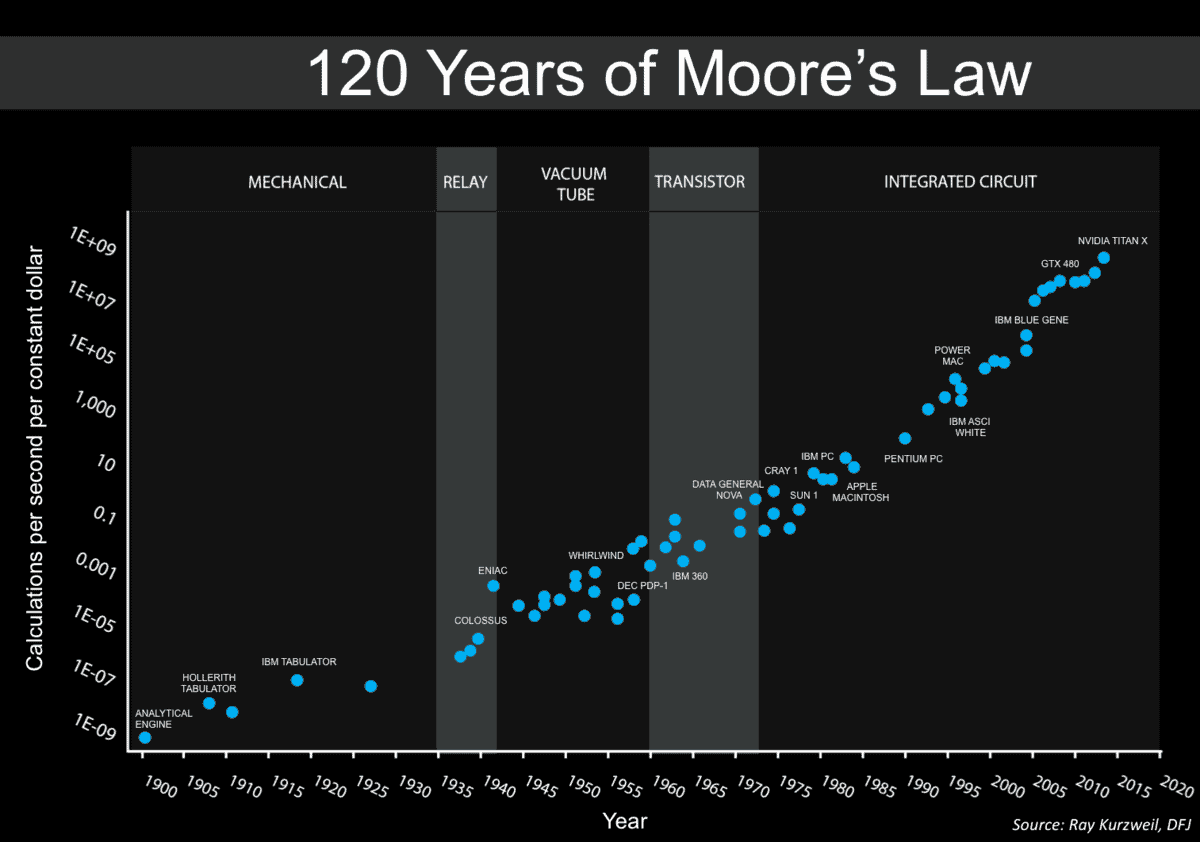
So, when will human-equivalent hardware be affordable?
To estimate the cost of human-level AGI, I looked at the estimates compiled by AI Impacts, and took the middle three estimates of FLOPS needed (10^16 to 10^22), for a price (in 2015 dollars) of $1,000/hour to $1 billion/hour.
If AI progress were highly predictable, and if human-level AGI were expected to have major impacts on world powers, I can imagine a few large organizations (such as US or Chinese military) might pay nearly $100 million/hour for human-level AGI. But given more realistic limits to predictability, I’d expect everyone will wait until the cost drops to the $100,000 to $1 million/hour range. Note that the later it happens, the higher numbers are more plausible, due to economic growth having made more wealth available. But that is somewhat offset by declines in the costs of hardware being slower in scenarios where AI is relatively hard.
That implies an upper bound of about 4 orders of magnitude price drop needed, and given an upper bound of 12 years to get each order of magnitude drop, I get a rough upper bound of 2015 + 48 = 2063. That’s far enough in future that I have almost no confidence in my ability to predict whether the cost of computing will still be declining, or how much money large organizations will spend on human-level AGI. But it represents the tail end of what should be something like a bell curve probability distribution whose peak is decades earlier.
Using numbers close to the midpoints (10^19 FLOPS and a willingness to pay $500,000/hour), I get an estimate of approximately now. And I get a lower bound of more than a decade ago. Although that $500,000/hour estimate seems higher than what any organization appears willing to pay now.
How does human-equivalent computing power affect the timing of human-level AI? Part 1: Human learning times
If hardware is the most important limit to developing AI, does that mean we’ll have human-level AI almost immediately after some organization is able to afford one?
Probably not. Training ML algorithms requires substantially more cpu time than running them. It seems likely that developers will need to do something that resembles raising a child, and will need to try that many times before getting a good enough starting point [3].
How efficient are primate brains at learning? In particular, is there a strong reason why large primates take years to learn enough to support themselves via foraging? I expect evolution optimized fairly well for fast development of the cognitive functions that have long been necessary for primate success, so the rate at which primates mature seems like moderate evidence against the feasibility of substantially faster algorithms to bootstrap primate-level intelligence. But primate development is also limited by the rate at which body parts grow, and I can’t rule out the possibility that that is somehow constraining cognitive development.
There are certainly kinds of knowledge for which that learning is data limited (e.g. infrequently used words), but there are important kinds of knowledge for which infants get plenty of data, such as object permanence, walking, and throwing objects. There seem to be large evolutionary advantages for infants to learn those things fast. So what limits the rate at which they learn?
You might imagine that the young primate wastes a lot of time with feeding, play, and sleep.
People often underestimate the value of playing. It seems likely that play is a valuable source of data. It seems likely that a young AGI will need to do something similar, although it’s possible that primate play is slowed by physical constraints that aren’t very relevant to AGIs.
Sleep is the most time-consuming activity for young primates, and younger ones seem to need more than older ones. Sleep saves muscle energy, but uses the same (large) brain energy consumption as when waking. That hints that the brain does something important during sleep, possibly something that infants need more of than older primates.
The semi-famous paper Why There Are Complementary Learning Systems in the Hippocampus and Neocortex: Insights From the Successes and Failures of Connectionist Models of Learning and Memory suggests that the hardest [4] parts of learning (i.e. generalizing, and constructing high-level models of the world) happen mostly via “off-line” replay of experiences.
These considerations lead me to suspect that young primate brains are devoting a least a few hours per night, and quite possibly over 12 out of every 24 hours, to generating general-purpose models of the world. And that an AGI which is trained from scratch will need to use algorithms that take comparable amounts of cpu power. So I’m guessing that it will take 1 to 3 years of human-equivalent cpu power to generate an AGI that matches most of the cognitive abilities of a 5-year old human.
Part 2 – translating that into a forecast
How many trials of growing an AGI to the equivalent of a human 5-year old will developers need in order to find one that grows up to have at least as much general intelligence as an average human adult?
Much of the development of general artificial intelligence seems likely to be done with systems that require at most months of near-human-equivalent hardware time. I expect a modest number of features of fully human-level AGI will require testing with full human-level hardware in order to get those features right, but I expect they’ll look more like the kind of “add-on modules” that enabled proto-humans to better transfer knowledge between one another. (AGI will require very different “modules”, because near-human AGI will have different weaknesses than proto-humans).
I’ll guess that full human-level AGI will require 10s to 1000s of those trials (1 to 3 years of human-equivalent cpu power).
How many of those can be done in parallel? Initially few, as nobody will pay for many. But if it takes more that a decade, an increasing number will be done in parallel, as costs decline and more wealth becomes available to throw at the problem. That suggests something like 10-30 years between the first use of human-equivalent cpu power and fully human-level AGI.
Conclusion
This analysis suggests that the probability of human-level AGI being reached in any given year has become nontrivial now, will reach a peak in the mid to late 2030s, and if it isn’t reached by 2100, then my approach here will have been mistaken.
That’s a wider time range than I expected when I started writing this post, and I haven’t even tried to articulate how model uncertainties should increase that range.
And I’ve arbitrarily assumed that human-level AGI is an important threshold. I suspect that assumption is not quite right, but improving on it seems hard.
I neglected the forecasts of AI researchers and evidence from recent AGI milestones while writing the main parts of this post, in hopes of generating insights that are somewhat independent of what other forecasters are producing.
But now I’ll incorporate that evidence: I suspect AI researchers could see human-level AGI coming soon if it were less than 5 years away. Yet they seem to talk and act as if it’s farther in the future. And the most impressive AI systems seem only able to beat human performance on fairly special-purpose tasks or tasks where I don’t expect humans to have been heavily optimized. So I’ll set a lower bound of about 5 years from now for human-level AGI.
I haven’t been influenced much by longer-term forecasts from AI researchers, due to indications that those forecasts are unreliable.
I’m a bit disappointed that this effort hasn’t helped me decide how urgent AI safety is, but at least it has clarified my thoughts about why I’m uncertain.
Footnotes
[1] – his model predicted that “parallel algorithms will continue to improve as fast as before, but serial algorithm gains will slow down.” The evidence in the 4+ years since that prediction seems pretty consistent with that prediction. But I don’t suppose it was a surprising prediction at the time.
[2] – that seems mostly due to changes in how users want to trade off speed for longer battery life, fan noise, etc., and not much due to inherent limits on clock frequencies. E.g. I used to buy computers mainly for fast processing. But I just switched to a Pixelbook that has a much lower clock frequency than my prior main computer, because fan noise has been bothering me more than slow software. I like the change a lot, even though I still need more than half an hour to run some fairly urgent tasks every weekday evening.
[3] – I assume it will be possible to reuse some pre-trained subsystems rather than re-train the entire system from scratch. But that doesn’t seem common in existing ML research, which I take as weak evidence that it doesn’t save much time or money. That’s probably because the subsystems that are most expensive to train are the hardest to integrate with the rest of the system.
[4] – hardest as measured by computing power, not the difficulty of developing the algorithms.
Pingback: Rational Feed – deluks917
Yes it is plausible that data on algorithms improving with hardware are selected for where algorithms don’t run out.
On hardware, we’ve already seem timing gains stop, but cost gains have not slowed as a result. It may be that cost gains won’t stop when feature size limits are hit as well. But even assuming cost per gate falls at the same speed, after the “Landauer limit” such gains will have to be split between more time per operation and more operations. So after that point effective progress may go half as fast.
On learning, ti seems that you are assuming that a simple general learning mechanism is sufficient; there won’t be lots of specifics to discover about how to learn particular things. I’m skeptical of that.
Hey, people!
Landauer’s limit allows us to have ~100 exaflops per Watt at room temperature.
Moreover, it allows us to have ~10 000 exaflops / Watt at cosmic microwave background temperature.
Why do you mention that “restriction” at all?
I think that for AI safety we need to look not on median arrival time but on the first 10 percent probability. To the median arrival time we will be dead with 50 percent probability.
I analysed other evidence, like the neural net performance growth and dataset size growth against “human size dataset” in the nonfinished yet article and in the presentation here: https://www.slideshare.net/avturchin/near-term-ai-safety
And come to similar conclusions about timing of first infra-human AIs: 2020s.
However, after first infra-human AI I expect that the curve will change because higher investment and lowering prices for specialised hardware will increase the number of tested infrahuman designs very quickly, so thousands will be tested in 1-2 years after first one.
Robin,
I think I agree with you (and disagree with Eliezer) that an AGI will need lots of specifics. I get the impression that we disagree mainly about the extent to which those specifics require human work to implement.
I see a trend toward increased use of learning as opposed to having knowledge built in. E.g. humans learning from culture what to eat, versus some innate knowledge of what to eat in other primates; or Google Neural Machine Translation replacing software which depended more on humans telling it how language works. I expect this pattern to continue, so that systems with more computing power and data will acquire increasing fractions of what you call specifics without human intervention.
Questioner,
I mentioned the “Landauer limit” because it’s expected to have some important effects on how Moore’s law works. I’m unsure why I mentioned Koomey’s law – FLOPS/watt doesn’t seem important in the most likely AGI timeframes. Also, experts seem confident that cooling below room temperature won’t save money.
Thanks for writing this. Great read.
Your footnote #3 not withstanding (maybe I missed the argument), if the learnt algo becomes easily reproducible/transferable across new AI instances, then shouldn’t the cost of learning be somehow amortized against all present and future AI instances that use that algo?
Another factor to consider is the notion of collective intelligence. That is, the idea that multiple weakly communicating instances can be better problem solvers than a single instance with the same computing resources. If this turns out to be the case (as some recent papers suggest), then there’d be every incentive to make this learning transferability work and deploy many (still learning) AI instances from “pre-learnt” instances.
Thanks for the detailed analysis, and apologies for the nitpick on an otherwise very interesting post, but I think you mean to say that cerebral cortex mass scales polynomially, not exponentially, with number of neurons. If the power is fixed but the base varies, then you have polynomial growth. It looks to me like the rest of your discussion treats this correctly, so probably this is just a matter of terminology.
It’s just an aside, largely irrelevant to the main point, but Footnote 2 seems wrong to me, though I’m not quite sure what you’re saying. Yes, there are no hard limits on clock speed, and actual choices depend on tradeoffs, but the tradeoff curve really has changed. It is true that phones sacrifice clock speed for other goals. Laptops, too, to a lesser degree. But desktop and supercomputer clock speeds ceased increasing because of technical problems. Dennard scaling meant that every time transistors got smaller, you could increase clock speed while keeping the power consumption (per area) the same. But it broke down.
Babak,
When I said “hardest to integrate with the rest of the system”, I meant to suggest difficulties which will recur each time a moderately new AI version is created. But my intuitions are fairly vague here.
The collective intelligence approach seems likely to offer some benefits, but I find it hard to imagine they’ll have a big effect on the timing of human-level AGI compared to the other sources of uncertainty.
David,
Thanks, I’ve fixed that.
Douglas,
Yes, it looks like I overstated the importance of changing user preferences.
Yes, a system that starts out with a simple learning algorithm of course ends up with lots of specifics. But my claim is that to learn well a system needs to start out with a lot of the right sort of specifics at the learning level. Yes, even with the right learning approach it could take a system many years to reach maturity. But it could take many times longer to search to find the right sort of learning approach. The more detail is needed in the right approach, the longer it should take.
I have an argument about evolution to make. Current deep neural networks are evolving in a few weeks what took biological systems millions or billions of years to evolve. They are basically learning the lower visual pathways and upwards far more efficiently than is possible with biological evolution. Mainly because digital systems are more finely quanititized than biological systems.
I made some comments on the Numenta website about it:
https://discourse.numenta.org/t/omg-ai-winter/3195
The thing that is missing from current deep neural networks is connection to vast (associative) memory reserves. Also backpropagation may be a little too weak for wiring everything together but very simple evolutionary algorithms will do where there are a large excess of parameters.
If you can accept that digital evolution is far more efficient than biological evolution then AI can push way beyond human capabilities in fairly short order, even on current hardware.
I’d like to build on Babak’s observation about collaborative intelligence. Disclosure: I’m Chairman and lead investor in a company that just released an open source architecture for building collaborative intelligence networks, so I’ve drunk the Koolaid.
To me, AGI is misguided from the start because in fact humans don’t have “general intelligence.” Our entire physiology is a network of special-purpose cells and subsystems. Our brains are kinda general purpose but through learning develop specialist areas, and they interconnect to a network of nerves that become specialized subsystems.
And we’ve evolved as a species because of language, collaboration and specialization. Nature, nurture, culture, education and economics foster specialization across the population.
An important part of our evolution is due to abstraction at various fractal layers of physiology and culture. Our consciousness doesn’t process every pixel our eyes see, every sound wave our ears hear. Our consciousness isn’t aware of everything our body does. Only abstractions of concepts or emotions rise all the way up. That’s an efficient architecture.
And that’s why ML isn’t the path to AGI, IMO. Networks of specialized MLs, combined with other types of AI, bring computational efficiency through distributed network architecture rather than through centralized algorithms.
Those networks may include Bayesian learning trees, fractal abstraction networks, and competitive evolutionary ecosystems. Math, economics and ecology offer a variety of architectures. None of them are “general purpose” in the sense that they provide “most likely the best” answers in all contexts.
But contextual specialization does lead to efficiency of the system.
Babak referred to “weakly communicating instances.” A microservices architecture configured in a Bayesian or fractal network can create “strongly communicating instances.” Or if self organized criticality yields emergent most likely best choices, then a weakly communicating network is a better network architecture.
It’s possible (likely?) this principle also applies to hardware. Way out of my league here, but from afar it seems like special-purpose architectures outperform general purpose ones in well-defined contexts. CPU/GPU/TPU is just one of many examples. Perhaps increasingly specialized AI hardware will approach the cost of general purpose AI hardware over time through automation, yielding price/performance improvements not shown in a forecast of extrapolating the general purpose approach.
Not sure what that means for your forecast.
If this stirs curiosity, you can learn more at https://www.introspectivesystems.com/
Pingback: Where Is My Flying Car? | Bayesian Investor Blog
Does anyone have any updates wrt developments in compute? E.g. a TPU v3 pod has 90 PFLOPS which is withing the mentioned range [10^16, 10^22]. Any thoughts?
https://en.m.wikipedia.org/wiki/Tensor_processing_unit